Daniele Fanelli

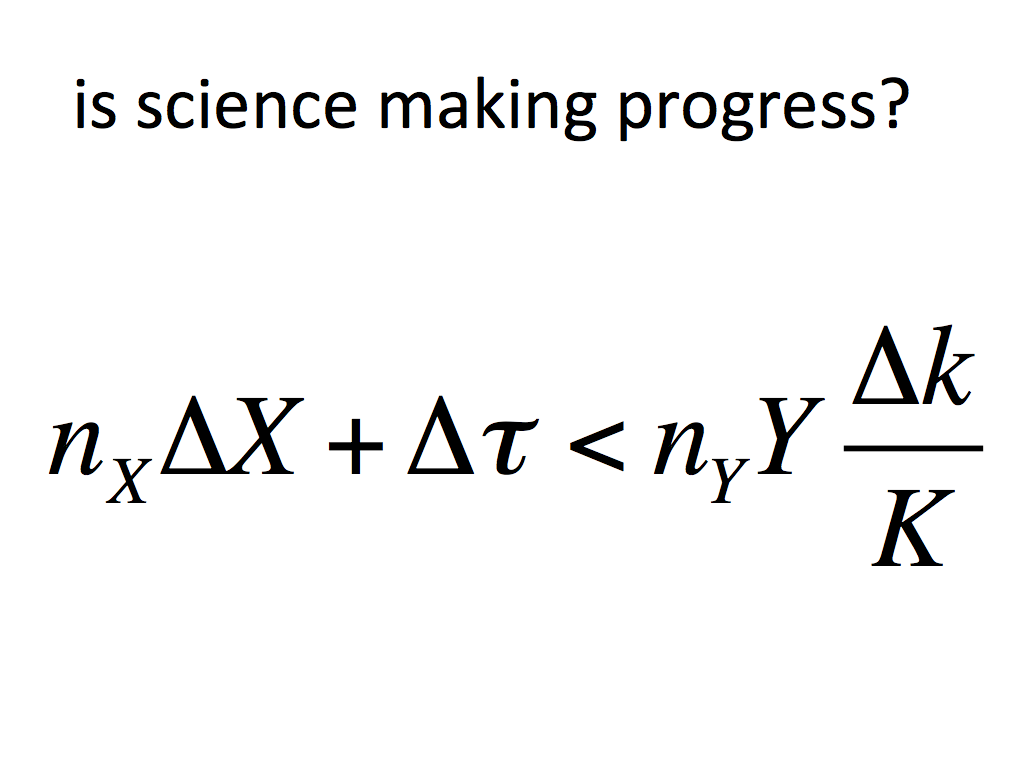


- 17-12-2020: Probing academic consensus on COVID-19 mitigation strategies - Are lockdown policies favoured mainly in high-income countries?
- 4-2-2020: A short interview with New Scientist on my participation to the NAS conference
- 19-4-2017: "Reproducible" is not synonymous with "true": a comment on the NAS report recommendations
- 7-4-2017: Maturing Meta-Science Was On Show In Washington DC
- -
- -
Probing academic consensus on COVID-19 mitigation strategies
Are lockdown policies favoured mainly in high-income countries?
London, 17 December 2020
What do experts think about COVID-19 mitigation strategies? I mean, literally, how can we know what they really think, right now, across disciplines and countries?
Take national lockdown policies as an example. In one form or another, they have been adopted by most countries around the world, suggesting a strong consensus around their necessity. It is presumably on this basis that the public expression of contrary opinions is discouraged, especially when voiced by prominent scientists, who are seen as unwitting agents of misinformation. And when alternative strategies are proposed, such as the "focussed protection" model outlined in the Great Barrington Declaration (GBD), reportedly signed by nearly 13,000 medical scientists and three times as many health practitioners, these are cast aside as a fringe viewpoint that does not reflect the scientific consensus.
It may well be that current policies side with the scientific consensus. But are we measuring such consensus, and how? In which disciplines? In which countries? Moreover, aren't scientific opinions amenable to change over time, as more evidence is gathered about such a new and complex problem? And how eaasily can this change of belief occur, if dissent is publicaly discouraged?
Lest anyone doubts it, the problem of misinformation online is real and serious. However, so is the risk of stifling progress by silencing public debates. Moreover, and perhaps most importantly, any action that can be construed as censorship will reinforce conspiratorial narratives and enlarge the only "fringe" that should really concern us all - that of irredeemable 'denialists'.
Inspired by these considerations and by genuine curiosity, a few weeks ago I decided to experiment with a new way to assess and disseminate if and how experts agree on complex issues like this one. The idea is simple enough, and it involves a combination of systematic review, online survey and social media methodologies.
I created a public platform where a selected group of experts could answer a specific question anonimously, by using a secret key known only to them. Their answers are displayed on the site, in aggregated and anonymized form, and their optional comments are shown. If they wish to change their answer or input a new comment, they can do so at any time. This approach meets three objectives at once: it informs the public about what academics think about a relevant problem, it helps experts communicate freely, and it produces data about how scientific consensus varies across contexts and over time.
A few technical hurdles and multiple ethics revisions later, and welcome to covidConsensus.org!
Selection criteria were intentionally broad, in order to capture a large diversity of perspectives. As displayed in the flow-diagram, I identified from the Web of Science database 1,841 corresponding authors of articles that in title or abstract included any one of a set of key-words relevant to COVID-19 mitigation strategies. That's all. No arbitrary rules involved.
Each author in the list, which is also displayed online for transparency, received an email invitation that included a personal code and all the data that was associated with the anonymyzed code: research field, country and gender. They could ask to have the data corrected or not to be included at all.
The question asked was designed to be simple and unambiguous:
to what extent do you support a 'Focused Protection' policy against COVID-19,
like that proposed in the Great Barrington Declaration?"
with answers collected on a 5-point Likert scale from "none" to "fully".
Excluding the undelivered emails, a total of 1,755 invitations were sent. At the time or writing, 453 respondents (25.8%) visited the website at least once, spending on average one minute on it. Of these, N=97 (21.4%, 5.5% of invitations) posted an answer, for a total of 132 votes and 58 comments. A small group of countries yielded zero contacts, suggesting that emails failed to reach their authors, perhaps filtered out as spam. However, the remaining country numbers were correlated with the total number of invitations, suggesting an adequate capturing of the target population.
The response data above suggest that participants have voted deliberately. In many cases, they chose not to vote at all after visiting the site, thereby taking an interest in the project. In other cases, they voted multiple times. At least one author did so in an obvious attempt to "game" the results, inputting "none" 15 times in a row. Unfortunately for them, all analyses are based on the last vote cast by each voter-code, making such stratagems futile.
So what are the results, you ask? Offring here a preliminary analysis of the descriptives of all groupings and trends shown on the site, answers are rather spread out and were, right from the beginning of data collection, bimodally distributed around "none" and "partially". In other words, few appear to fully endorse the GBD, but at least as many are in partial agreement with its principles as they are entirely opposed to it.
What level of consensus does this reflect? To measure it, we can use a simple measure of "proportional entropy explained":
where H(Y), is the Shannon entropy (information content) of the distribution of answers Y. This is a simplified version of a K function that I elsewhere proposed as a general metric of knowledge. Consensus is full when k=1, and all respondents give the same answer, whatever that answer is. Conversely, k=0 means that all answers are equally likely - in other words, we have no idea what any one thinks. Applied to all aggregated data, consensus is surprisingly low (Figure 1).

Figure 1
Let's be extremely clear that this does not entail low consensus by scientists on COVID-19 policies - not only because the sample size is small, but also because answers come from a very diverse pool of experts, with different social and academic backgrounds.
But this is precisely where things get interesting, because both agreement and consensus vary significantly across disciplines, countries and even gender of experts! Looking only at categories where five or more votes were cast, it would seem that female authors tend to be less favourable to focussed protection than males and/or authors whose gender cannot be determined based on first name (Fig 2).

Figure 2
Disciplines also show remarkable differences. In particular, authors of articles in social science or humanities journals have low consensus and/or spread-out distributions overall. Authors in clinical medicine, however, show a strong preference towards "partially" agreeing. This is unlike authors in the remaining 18 disciplines (aggregated here as "other") which have similar levels of consensus but are relatively against focussed protection (Fig 3)

Figure 3
Most intriguing of all, there are significant differences between countries. Authors in India, for example, are much more favourable than others (Fig 4).

Figure 4
What could explain the sharp difference between countries? The two principal areas of contention in the debate on lockdowns are centered on economics and demographics. On the one hand, there are fears that lockdowns might have devastating economic impact and increase inequality within and between countries. On the other hand, the focussed protection idea of shielding only the most vulnerable is criticized as unethical and unfeasible, especially in conditions of extreme poverty and forced cohexistence. This tension was reflected in many of the comments posted on the website, too.
I explored the relative importance of these two dimensions with a multivariable ordinal regression model that included two country variables taken from 2019 World Bank Data: per-capita GDP and the percentage of population over 65. The former is a proxy of economic factors, and the latter of demographic ones. Controlling for discipline, the strongest predictors of agreeing with a focussed protection strategy are per-capita GDP, and gender (Fig 5).

Figure 5
These two effects are striking. For example, this is how they relate to the predicted probability of agreeing, for an author in clinical medicine, from a country with 10% over-65 year olds:

Figure 6
Although preliminary and derived from a relatively small sample, the relation with GDP seems to offer some support to the economic argument advanced by the GBD. We can hypothesize that scientists in poorer countries are most in favour of it because they are most painfully aware of the economic impact of shutting down local and global economies.
The gender effect is harder to explain, especially against suggestions that female academics pay the heaviest career price due to lockdown policies. We might speculate that women, who tend to take on greater responsibility for the care of dependents, are more protective than their male counterparts. However, their could be hidden confounding effects, for example if females are over-represented in subfields that tend to oppose focussed protection.
Textual analyses of the comments section, and perhaps analyses on more data, might help assess these interpretations. However, beyond the specific results, which are clearly limited, this project illustrates the importance of probing and studying scientific consensus on matters of societal or scientific controversy, and it also illustrates some of the challenges in doing so. The experience accrued in this pilot will help me build a better and more effective platform, where newer questions will be addressed.
But if you, dear reader, have received an invitation code and haven't voted yet, please be inspired to do that now, and let everybody know what academics really think.
A short interview with New Scientist on my participation to the NAS conference
London, 4 February 2020
The dust has luckily settled, and a few reflections are due. It was less than a month ago, that a budding Twitterstorm seemed bent on engulfing myself and other respected colleagues, guilty of having accepted the invitation to speak at the forthcoming conference of the National Academy of Scholars (NAS), aimed at "Fixing Science". Amidst factitions accusations of sexism, racism and science denialism, most of the speakers and I decided to hold our ground, concerned as we are that echo chambers enfored by a cancel culture might constitute a greater threat to science than reproducibility issues could ever be.
The NAS president Peter Wood had written, a few weeks ago, a convincing response on the Wall Street Journal to the accusations. And it may be a telling sign that at least some of the Tweets that had tried to spark outrageagainst the event have since been removed. It remains to be seen how the conference will go, but I can report to have been inspired by this experience and by the numerous cases that have been less fortunate than ours, and intend to look more into this phenomenon. In the meantime, I thought I could share my replies to Michael Marshall, who wrote a story about the episode for New Scientist. Here they are:
What do we know about the reproducibility of modern science?
We know a lot more, but far from enough. We are still unclear about how to define the concept, let alone measure it. We have only studied these issues for a few years, and there are clearly numerous areas of uncertainty, debate and contradictory evidence.
Do the arguments you made in your 2018 PNAS opinion piece [...] still stand, or does more recent evidence require that they be modified?
They absolutely stand. Indeed, my PNAS article actually underestimated the contradictoriness of some evidence. Multiple studies reporting imbalances in P-values, for example, turned out to be not reproducible. And further recent reproducibility studies, for example one in Experimental Philosophy, concluded that the reproducibility rate was high. Which is what most other reproducibility studies have found. Therefore, setting aside many theoretical and methodological issues with how we define and measure reproducibility, it is really baffling that, faced with this kind of evidence, people remain adamant that "science is broken". Besides it not being supported by evidence, this crisis narrative is quite easily exploited for anti-scientific agendas of all types.
The point is not that there are no issues to address with contemporary research, but that framing them as a problem with "science" is simplistic and not supported by logic and evidence.
Are there particular disciplines of science that have a greater reproducibility problem than others? Where do the environmental sciences - notably climate science, biodiversity/conservation, and pollution - lie on the spectrum?
I don't believe that we have sufficient evidence to say so. I can say that both theory and evidence suggests that, all else equal, fields dealing with higher complexity are going to face greater challenges in general. But it does not follow that they are less credible or "reproducible". Rather, it is the meaning of the term "reproducibility" that becomes more complex and subtle. For example, in biology there are complex genotype-environment interactions. If these are not properly accounted for, results might appear to be inconsistent between study sites, even though they are perfectly true and replicable within-site. Such results might appear to be "irreproducible" by the current flawed standards of reproducibility.
Part of the problem is that the field of metascience lacks a paradigm that is truly meta-scientific, i.e. applicable across all fields. I have recently tried to propose a theory and methodology that might be able to help [...].
What contact have you had with the NAS prior to the upcoming conference?
My critique of the crisis narrative, as I call it, was published just a week before the NAS report that claimed science needed fixing. The NAS report of course exemplified perfectly the kind of errors and risks that I was warning about in the PNAS opinion. The NAS, to their credit, immediately invited me to write an opinion on their report. But I just wrote a few comments in a blog post that you can find on my website.
How did you come to be on the speakers list: did they invite you?
Yes. I made it clear that I would talk as a sceptic of some of the premises of the conference, and I also sought re-assurance that my participation will not be taken as an endorsement of any political position or agenda.
Do you regard the NAS and its key figures as essentially honest scholars, or as a campaign group engaged in science denial for political ends? (or some other characterisation!)
In my experience, they have expressed a genuine scholarly spirit. They have repeatedly solicited my opinion precisely because I don't seem to share their beliefs. This is commendable, and is what we should all do, as scientists and as citizens.
I may add that the NAS response to my PNAS article stands in ironic contrast to the attitude taken by many others, who are supposedly science advocates, and yet took to Twitter to attack my PNAS paper on purely emotional or personal grounds. I am still waiting for a scientific rebutting of my arguments.
I don't have direct evidence that the NAS is in "science denial", as you say. I understand that, as a whole, the NAS might have a certain political positioning, but they are certainly not alone, in this regard.
Are you aware that NAS has repeatedly attacked climate science as largely irreproducible, and argued on that basis against climate-related policies such as greenhouse gas emissions cuts?
I haven't looked into what they have written on this or any other topic. But everyone is entitled to their opinion. As long as someone invites a scholarly and civil dialogue, I will be keen to hear their arguments and rebut them if and to the extent that my expertise compels me to do so.
Do you accept that there are significant similarities between the NAS and existing science denial movements, e.g. anti-vax, HIV denial?
If that were the case, I don't believe that they would have invited someone like me, who is one of the few open critics of their positions.
I understand the desire to rebut arguments you believe are false and to engage in open debate. However, by speaking at the NAS conference, "on their turf" so to speak, are you not bolstering their reputation?
Perhaps, but then are you, and all the other journalists and Twitterati who report on this conference not bolstering their reputation, too? If the exact same event had been organized by an entity with an opposite political agenda, none of this dust would have been raised. Yet, I would have taken part just the same, and with the exact same spirit.
Have you discussed your decision to attend with any specialists in science denial, and if so what was their advice?
No.
If I had any evidence that my participation in the conference was used for political gains, I would withdraw. If I garner such evidence during or after the conference, I will take all steps necessary to distance myself.
Sorry, I appreciate that's a lot of questions. I should add, if there are any additional points you want to make that aren't covered, please feel free to make them anyway!
No problem. I will be happy to answer other questions. And please do let me know when the article gets published.
[We didn't interact further.]
***
"Reproducible" is not synonymous with "true": a comment on the NAS report
London, 19 April 2017
The timing was almost perfect, and that’s not a coincidence. Only a few weeks after the publication of my opinion in PNAS, which warned against making unsupported claims that science is in crisis, the National Academy of Scholars (NAS) issued a report on the “Irreproducibility Crisis of Modern Science”.
I highly praise the authors of the report, David Randall and Christopher Welser, for inviting me to contribute an opinion on the matter. Such invitation epitomizes what I still be believe to be the only real antidote to bad science and misguided policies: an open and transparent scholarly debate.
The timing of this report is not coincidental because, as I illustrated in the PNAS article, the narrative that science is in crisis is spreading as we speak. Like other similar documents, the NAS report aims to make potentially constructive and interesting proposals to improve research practices, but justifies them on the basis of an empirically unsupported and strategically counterproductive claim that the scientific system is falling apart.
Before commenting on some of the 40 recommendations made in the executive summary of the report, I will very briefly restate that I see no evidence in the literature of an “irreproducibility crisis of modern science”. There is no evidence that most of the literature is hopelessly biased or irreproducible, no evidence that the validity of research findings has declined in recent decades, and no evidence that such problems are rising in the USA or other Western countries due to pressures to publish. I used to believe differently, but recent, better studies have changed my mind.
Make no mistake, the research and publication practices of many fields have plenty of room for improvement. However, as summarized in the PNAS article (an extended version of which is in preparation) the most updated research suggests that problems with transparency, reproducibility, bias and misconduct are highly irregularly distributed – across and within individual disciplines - and have equally diversified and complex causes. This makes me extremely skeptical, indeed weary, of any recommendation to adopt “one size fits all” solutions. This is the main criticism that I have for some of the recommendations made by the report.
Many of the recommendations made by the report, I strongly support.
I emphatically agree, for example, with all recommendations to improve the statistical literacy of scientists, journalists, policymakers and indeed the general public (recommendations n. 8-12,28,33,34,35,39,40). If all of us had been trained in statistical thinking to the same extent that we were taught algebra and geometry, many ill-advised debates would dissolve, from within science as well as society, and the world would be a much better place.
I also endorse any recommendation to pay greater attention to the methodological solidity of results, to focus on the substantive (and not merely statistical) significance of results, and to staff government agencies, judicial system and the media with adequately trained methodologists and statisticians (n. 1,2,21,23,36).
I also generally endorse any recommendation to “experiment” with innovative research and publication practices (e.g. n. 5,15,17). The emphasis here, however, has to be on “experimenting” with, rather than “imposing” new standards.
This is why I disagree, to varying degrees, with most of the other recommendations made.
Most of the other recommendations explicitly or implicitly seem aimed at imposing general standards of practice, in the name of reproducibility, across all research fields. Such recommendations presuppose that reproducibility is a clear-cut concept, that can be defined and assessed universally, and that is substantially equivalent to the truthfulness, validity and generalizability of results. Unfortunately, this is not the case.
Far from conclusively measuring how reproducible Psychology or Cancer biology are, the recent reproducibility studies cited by the report (and others not cited, whose results are less known and more optimistic) have sparked a fascinating debate over how the reproducibility of a study can be measured, assessed and interpreted empirically. This literature is gradually unveiling how complex, multifaceted and subtle these question really are.
It is well understood, but too hastily forgotten, that research results may not replicate for reasons that have nothing to do with flaws in their methodology or with the low scientific integrity of their authors. Reality can be messy and complex, and studies that try to tackle complex phenomena (which is to say most social and biological studies) are bound to yield evidence that is incomplete, erratic, sometimes contradictory and endlessly open to revision and refinement.
Therefore, whilst recommendations such as “all new regulations requiring scientific justification rely solely on research that meets strict reproducibility standards” (n. 29) or “to prevent government agencies from making regulations based on irreproducible research” (n. 31) may be agreed in principle, in practice they are unlikely to work as hoped. At the very least, the standards and criteria mentioned ought to be established on a case-by case basis.
Methods can certainly be made more “reproducible”, in the sense of being communicated with greater completeness and transparency. Recommendations to improve these components of the research process o are unobjectionable, as is the suggestion to experiment with practices that add statistical credibility to results, such as pre-registering a study. However, no amount of pre-registration, transparency, and sharing of data and code can turn a badly conceived and badly designed study into a good one. Even worse, by superficially complying to bureaucratic reproducibility standards, a flawed study might acquire undeserved legitimacy.
Unfortunately, “reproducible” is not synonymous with “true”. If there was a simple methodological recipe to determine whether a research finding is valid, we would have found it by now. Ironically, the root cause of many of the problems discussed in the report is precisely the illusion that such a recipe exists, and that it comes in the form of Null Hypothesis Significance Testing. Behind the recommendation to lower the significance threshold to P<0.01(n. 20) I see the risk of perpetuating such a myth. A risk that I don’t see, conversely, in recommending the use of Confidence Intervals ( n. 3) and Bayesian thinking (n. 9).
For similar reasons, I am conflicted about calls to fund replication research (e.g. n. 19) or reward the most significant negative results (n. 22). These ideas are excellent in principle, but presuppose that we have universal methodological criteria to establish what counts as a valid replication.
If an original study was badly conceived, the best way to show its flaws is not to replicate it exactly, but rather to design a different, better study. Or, sometimes, it might be best to just critique it and move on.
***
Maturing Meta-Science Was On Show In Washington DC
Stanford, 7 April 2017
Meta-Research is coming of age. This is the energizing insight that I brought home from Washington DC, where I had joined the recent Sackler Colloquium held at the National Academy of Sciences. Organized by David B. Allison, Richard Shiffrin and Victoria Stodden, and generously supported by the Laura and John Arnold foundation and others, the colloquium brought together experts from all over the academic and geographic world, to discuss “Reproducibility of Research: Issues and Proposed Remedies”.
The title was great but, let’s be honest, it didn’t promise anything exceedingly new. By now, small and large events announcing this or similar themes take place regularly in all countries. They absolutely need to because, even though we seem to understand relatively well the biases and issues that affect science the most – as we showed in a recent paper – we are far from having an accurate picture of the issues at hand, let alone devising adequate solutions. Needless to say, it was an absolute honor and a real pleasure for me to take part as a panelist, with the task of closing the day dedicated to “remedies”.
Never judge a conference by its title. Something new was in the DC air – or at least that’s what I felt. That certain sense of déjà entendu, that inevitable ennui of the converted who is preached to, were not there. In their place, was the electrifying impression that debates were surging, that meta-science was truly in the making.
Every topic was up for debate and no assumption seemed safe from scrutiny. Talks, questions and discussions felt mature, prudent and pragmatic, and yet they expressed an exciting diversity of experiences, opinions, ideas, visions and concerns.
Much praise, therefore, goes to the organizers. The lineup of speakers cleverly combined meta-research household names - like Brian Nosek, and David Moher - our ex-visiting scholar whom we sorely miss – with voices that are less commonly heard in the meta-research arena. Lehana Thabane, for example, who discussed reporting practices, and Emery Brown, whose appeal to teach statistics in primary school ought to be broadcast the world over.
Most importantly, however, the program included reputable counter-voices. For example, that of Susan Fiske, who has been under fire for her “methodological terrorism” remarks and is now studying scientific discourse in social media. Or that of Kathleen Hall Jamieson, who warned about the public image damages caused by an exceedingly negative narrative about science. Videos of all talks are available from the Sacker YouTube Channel.
As I argued in my session, whilst we should definitely strive to improve reproducibility and reduce bias wherever we see it, we have no empirical basis to claim that “science is broken” as a whole, or indeed that science was more reliable in the past than it is today. We simply do not know if that is the case and the difficulties in defining and measuring reproducibility were well illustrated by Joachim Vandekerckhove, Giovanni Parmigiani and other speakers. Indeed, the very meaning of reproducibility may be different across fields, as our opinion piece led by Steven Goodman argued last year.
Despite, or perhaps because of these difficulties, the best evidence at the moment seems to me to suggest that biased and false results are very irregularly distributed across research fields. The scientific enterprise badly needs interventions in specific areas, but as a whole is still relatively healthy. This is also what my past studies on positive study conclusions, retractions, corrections, scientific productivity and our most recent meta assessment of bias suggest.
Moreover, we do not need to believe that science is totally broken to endorse initiatives to improve reproducibility. Alternative narratives were offered, implicitly, by some of the speakers. These include Victoria Stodden, who on the first day showed how computational methods (i.e. the field where the concept of “reproducible research” was invented) are pervading all sciences, bringing into them new standards of reproducibility. A narrative of industrialization of the research process was suggested by Yoav Benjamini and one of democratization of knowledge by Hilda Bastian.
My assessment of the condition of modern science could be wrong, of course, and my remarks were met by several skeptical comments by the public. These were naturally welcome, because only diversity and debate allow a research field to make progress and mature. Meta-science, this latest event proved to me, is certainly doing so.